
Popular
Sora AI – Text to Video
- Free Plan : Freemium (Free and Paid)
- Subscription

MovieChat aims to address the challenges of computational complexity, memory cost, and long-term temporal connections for long videos.
Recently, integrating video foundation models and large language models to build a video understanding system overcoming the limitations of specific pre-defined vision tasks. Yet, existing systems can only handle videos with very few frames. For long videos, the computation complexity, memory cost, and long-term temporal connection are the remaining challenges. Inspired by Atkinson-Shiffrin memory model, we develop an memory mechanism including a rapidly updated short-term memory and a compact thus sustained long-term memory. We employ tokens in Transformers as the carriers of memory. MovieChat achieves state-of-the-art performace in long video understanding.

The working principle of MovieChat mainly includes the following steps:
1. Preprocessing: First, the video is cut into a series of segments, and each segment is encoded to obtain the feature representation of each segment.
2. Memory management: These feature representations are then stored in memory. As new video clips are processed, memory is updated, old information is gradually forgotten, and new information is stored in memory.
3. Question answering: When a question is received, MovieChat will generate an answer based on the question and the information in memory. This process is done with a Transformer model that can process long sequences and generate responses accordingly.
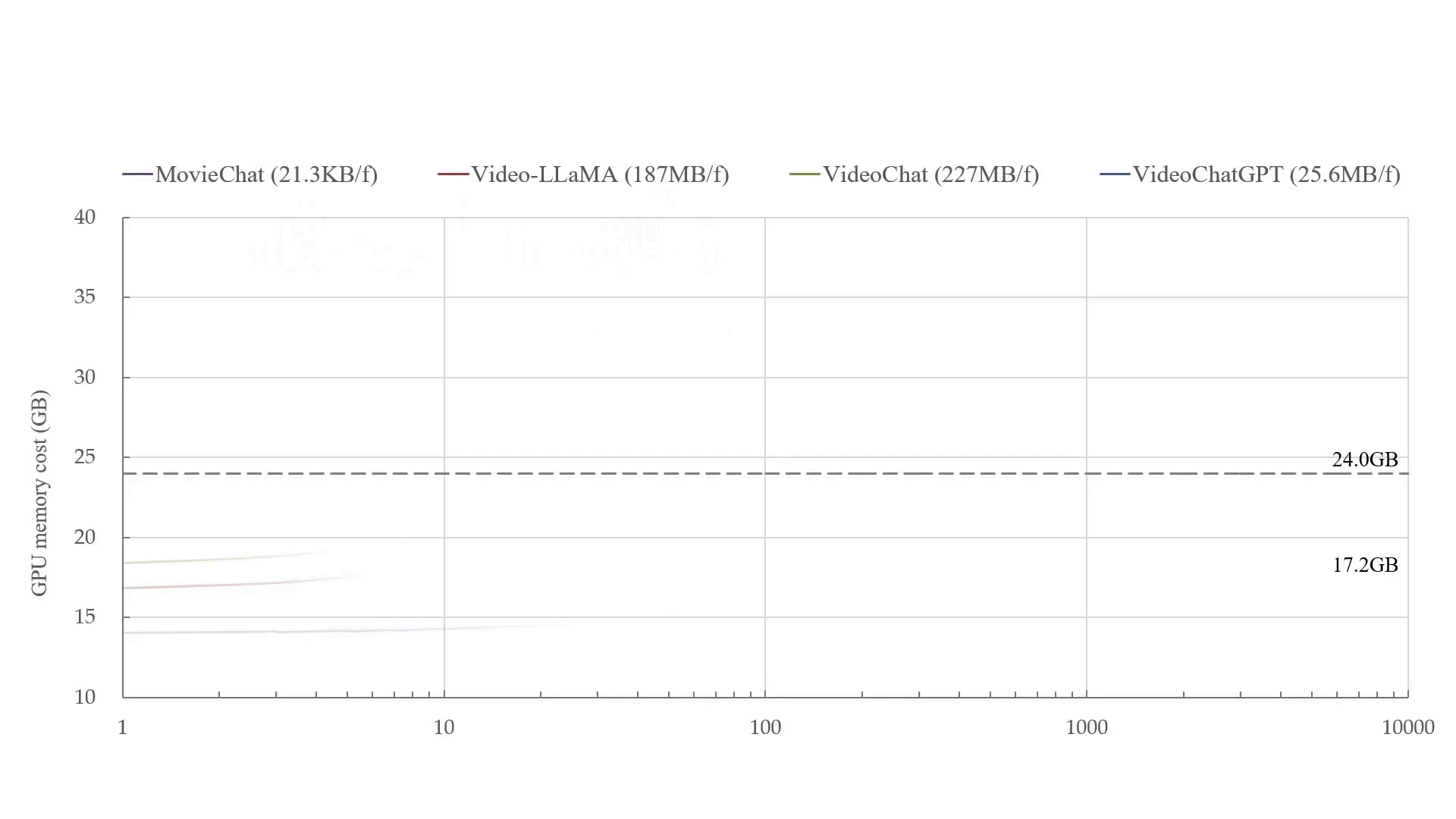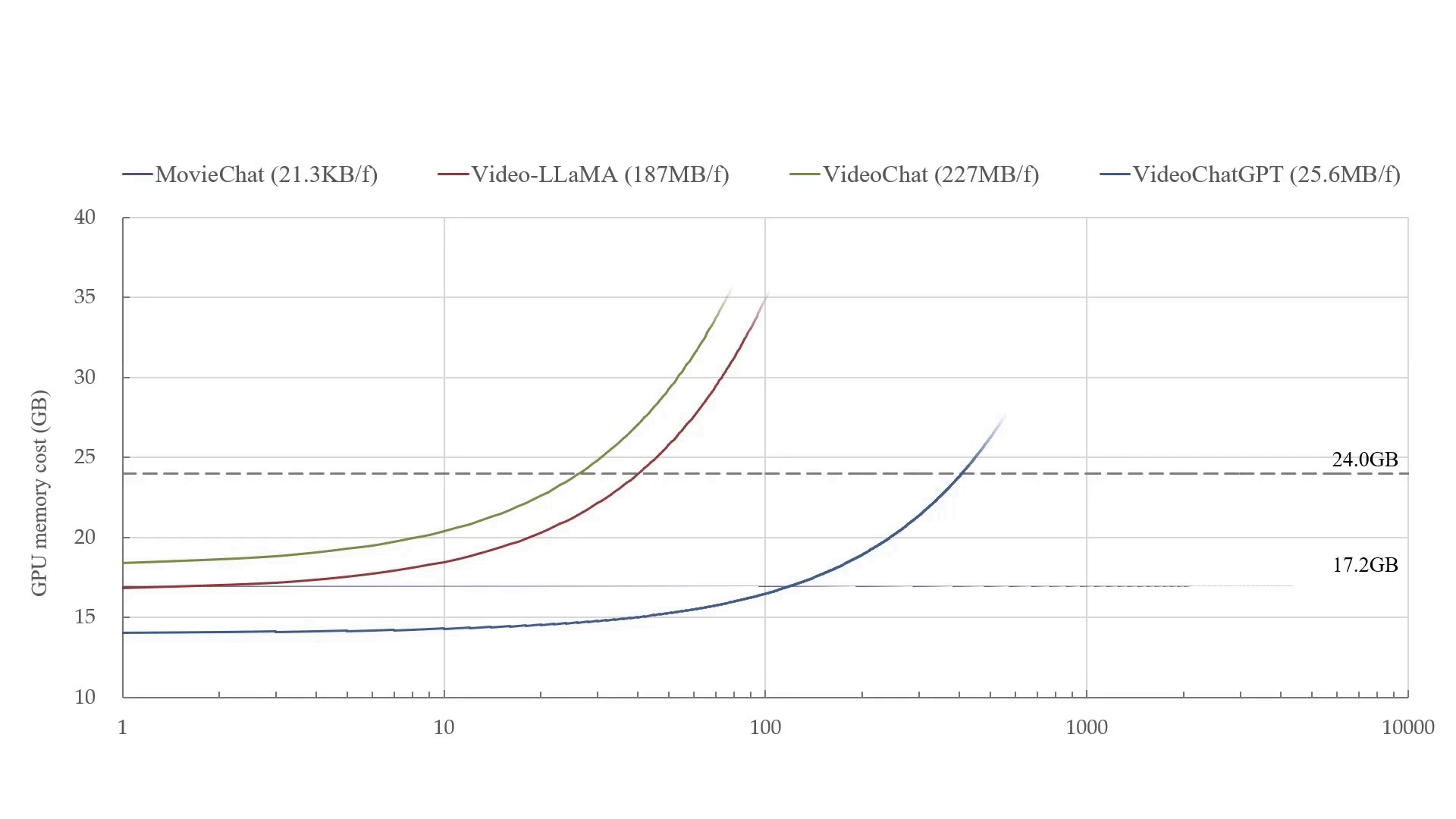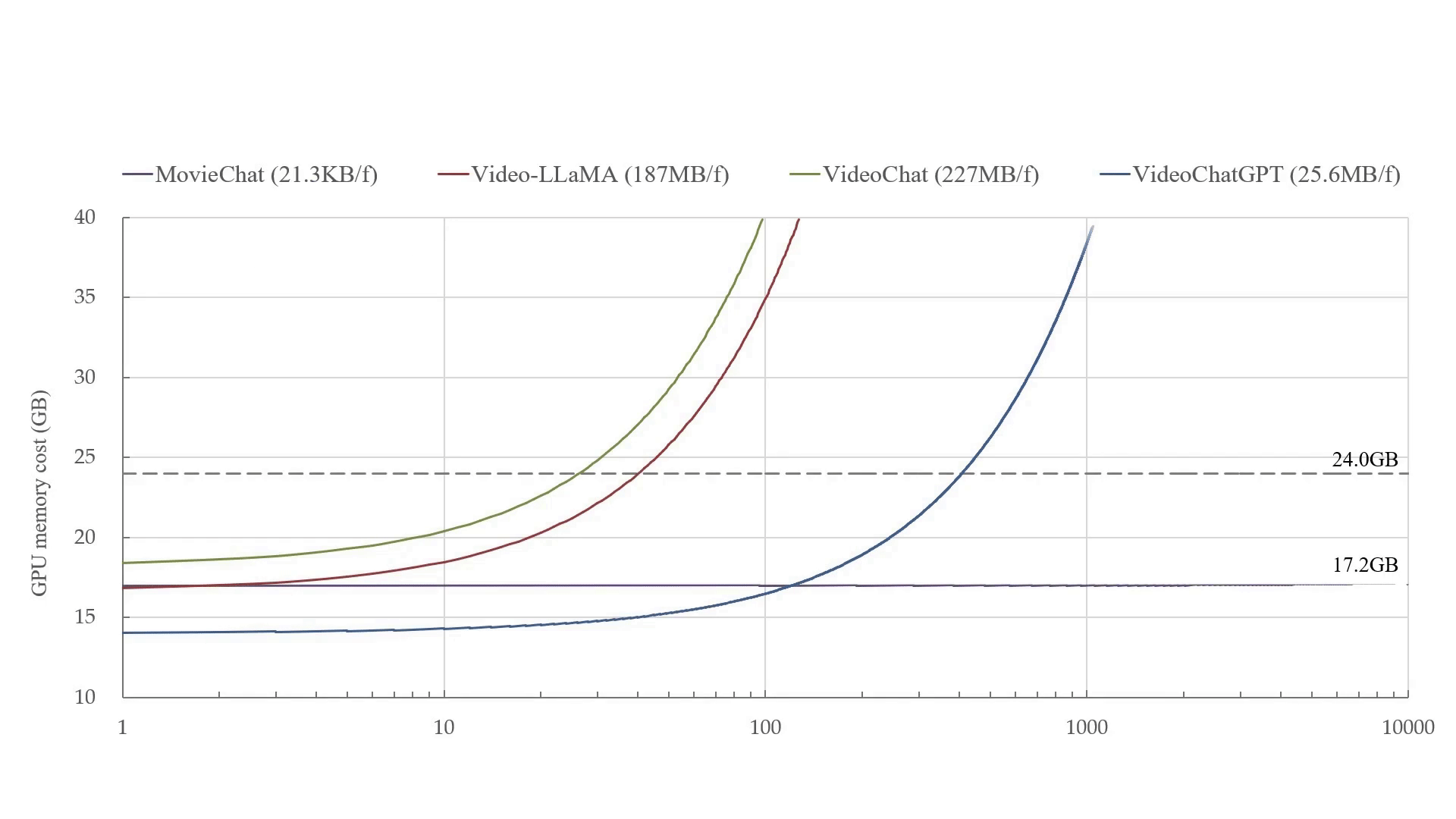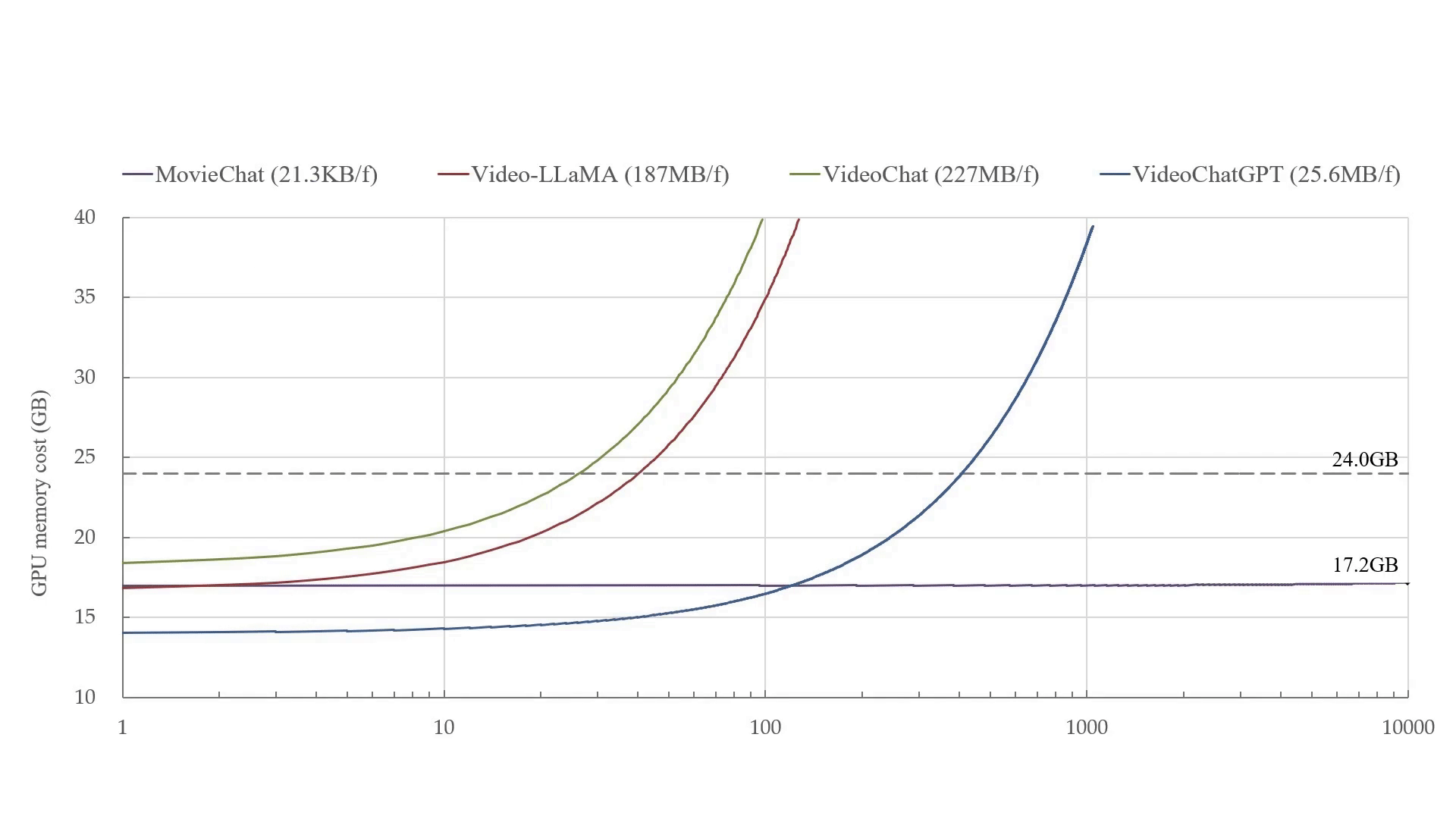
MovieChat can handle over 10K frames of video on a 24GB graphics card. MovieChat outperforms other methods by a factor of 10,000 in terms of average increase in GPU memory cost per frame (21.3KB/f to ~200MB/f).