
Popular
Carbon
- Free Plan : Yes
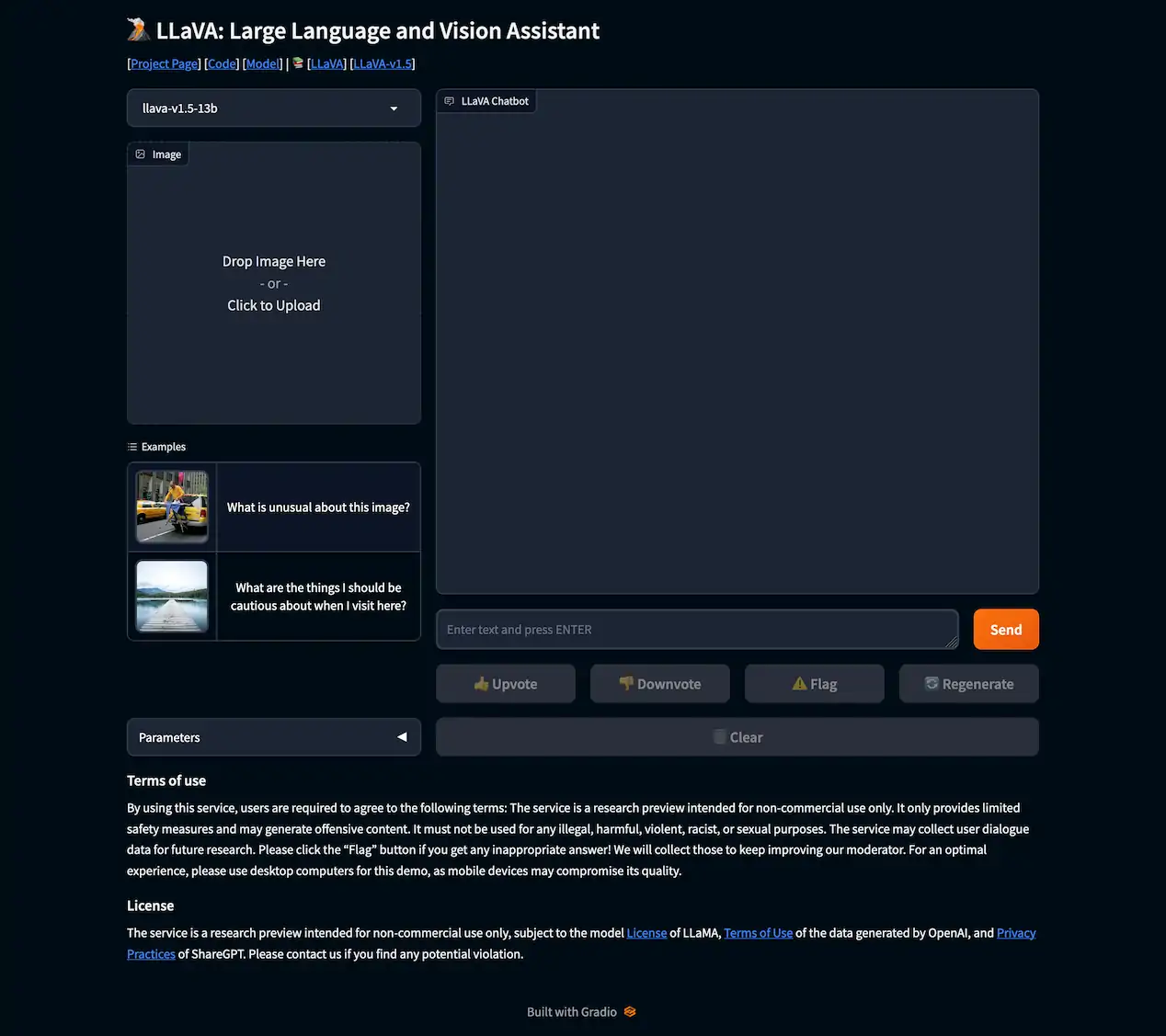
LLaVA is a large multimodal model designed to connect a vision encoder with a language model for various tasks involving both text and images.
You can access LLaVA and try out demos on their official website at llava.hliu.cc. Additionally, you can find the source code for LLaVA on GitHub at github.com/haotian-liu/LLaVA .
Overall, LLaVA appears to be a versatile tool for language and vision tasks, with active development and a community of users and developers. It combines vision and language processing capabilities and is being utilized for various applications, including image understanding and analysis.
LLaVA (Large Language and Vision Assistant) is an open-source, large multimodal model adept at integrating vision and language understanding. It sets a new benchmark in accuracy for ScienceQA tasks, demonstrating impressive capabilities similar to vision multimodal GPT-4.